There are several options when it comes to backing up a WordPress site. Depending on the type of access you have, retrieving the database or an XML backup is easy. But what if you don’t have access to the database or the backend? Consider the following scenario presented on the WordPress subreddit: A relative who used WordPress recently passed away and you have no way to access the backend of their site. Their site is filled with memorable posts you’d like to archive.
One option is to use WGET. WGET is a free, open source software package used for retrieving files using HTTP, HTTPS and FTP, the most widely used Internet protocols. I used version 1.10.2 of this WGET package put together by HHerold which worked successfully on my Windows 7 64-bit desktop. Once installed, you’ll need to activate the command prompt and navigate to the folder where WGET.exe is installed.
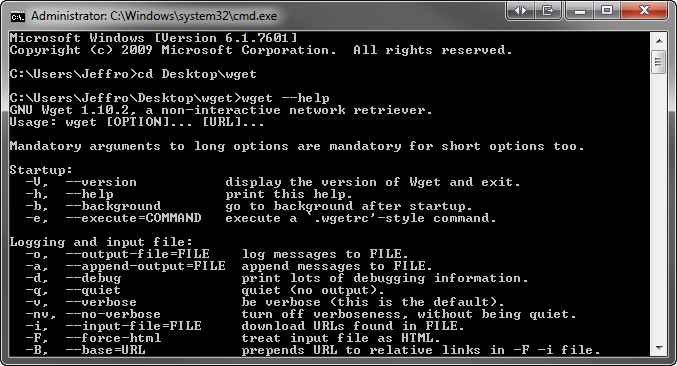
In the example below, I used four different parameters. GNU.org has an excellent guide available that explains what each parameter does. Alternatively, you can use the wget — help command to see a list of commands.
- HTML Extension – This will save the retrieved files as .HTML
- Convert Links – After the download is complete, this will convert the links in the document to make them suitable for local viewing. This affects not only the visible hyperlinks, but any part of the document that links to external content, such as embedded images, links to style sheets, hyperlinks to non-HTML content, etc.
- -m – This turns on the options suitable for mirroring.
- -w 20 – This command puts 20 seconds in between each file retrieved so it doesn’t hammer the server with traffic.
wget –html-extension –convert-links -m -w 20 http://example.com
Using this command, each post and page will be saved as an HTML file. The site will be mirrored and links will be converted so I can browse them locally. The last parameter places 20 second intervals between each file retrieved to help prevent overloading the web server.
Keep in mind that this is saving the output of a post or page into an HTML file. This method should not be used as the primary means of backing up a website.
The Command Line Proves Superior To The GUI
A popular alternative to WGET is WinHTTrack. Unfortunately, I couldn’t figure out how to get it to provide me with more than just the index.html of the site. I found WinHTTrack to be confusing and hard to use. I spent a few hours trying several different programs to archive the output of websites. Most were hard to use or didn’t provide an easy to use interface. While I normally don’t use the command line to accomplish a task, it was superior in this case.
Going back to our scenario, it’s entirely possible to archive a site you don’t have access to thanks to WGET and similar tools.
What tools or software do you recommend for archiving the output of a website?
wget will not pull information from a WordPress site fully secured by iThemes Security. Attempts to pull information from sites with iThemes or old installs of Better WP Security return 403 forbidden. Our sites using Wordfence do not seem protected from wget, but I have not looked into why this might be. This is a great solution to getting files and has come in handy countless times for our group, but if the target site in question uses iThemes Security fully, this is a no go.