If you’ve been wearing out Unsplash images on your blog, it’s time to take another look at Creative Commons. The site has just launched the beta of its new multi-source search interface. Unlike the current search tool, which will only search one source by sending the visitor offsite, CC Search loads the results from multiple sources onsite.
The Commons includes approximately 1.1 billion works in various formats – literary works, videos, photos, audio, scientific research, and other formats. As half of these works are estimated to be images, the prototype for the new search tool focuses on this format.
“Our goal is to cover the whole commons, but we wanted to develop something people could test and react to that would be useful at launch,” Creative Commons CEO Ryan Merkley said. “To build our beta, we settled on a goal to represent one percent of the known Commons, or about 10 million works, and we chose a vertical slice of images only, to fully explore a purpose-built interface that represented one type but many providers.”
CC Search currently pulls CC-licensed images from Rijksmuseum, Flickr, 500px, the New York Public Library, and the Metropolitan Museum of Art. This includes 200,000 new images from the collection of 375,000 digital works that the Met released under CC0 this week.
In addition to the new search interface, the beta includes social tools that allow users to curate and share their own lists, add tags and favorites, and save searches. One-click attribution is built in, making it easy for users to properly attribute the works.
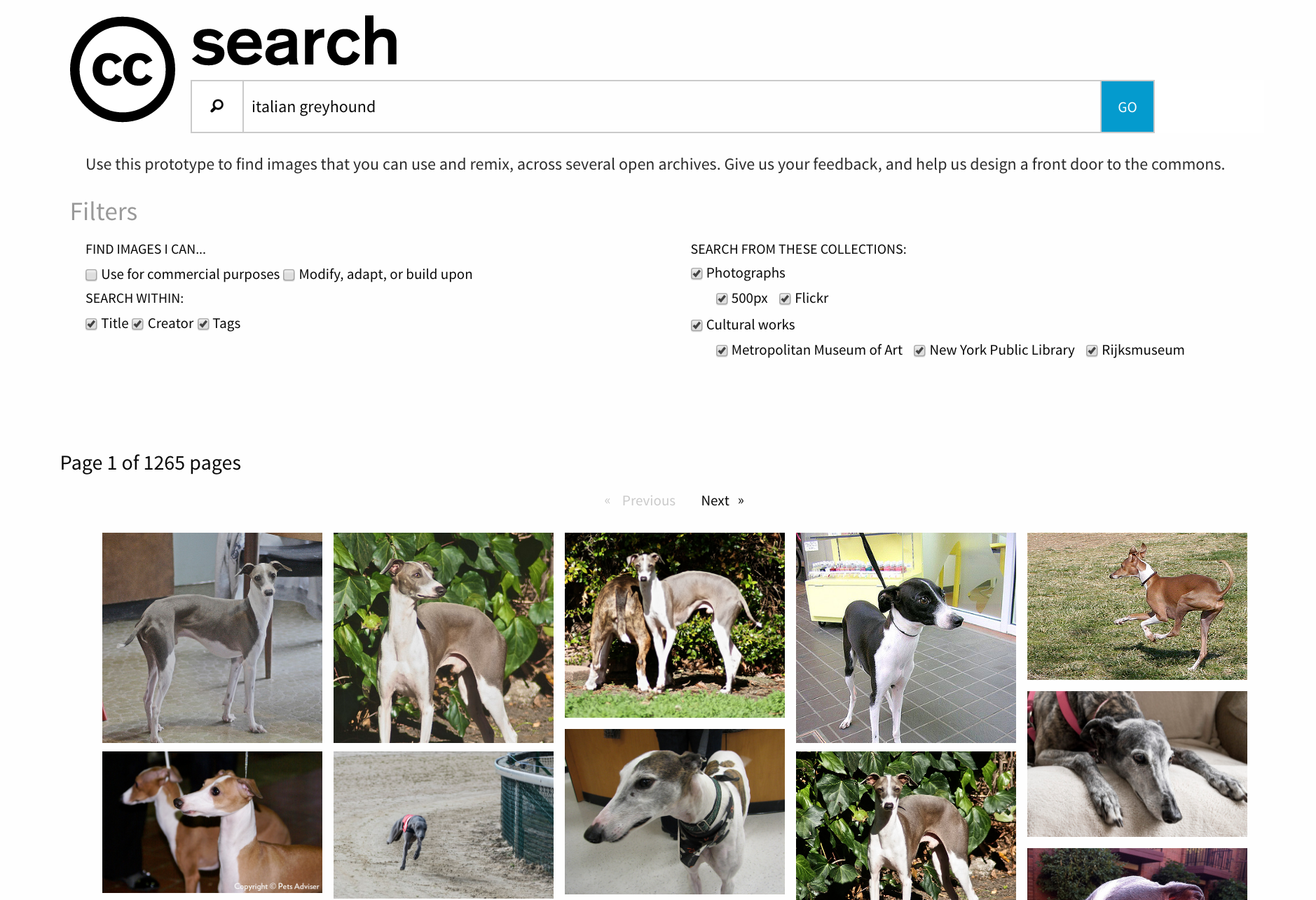
As Creative Commons is a small organization and fairly lean on resources, the new search was built by a single contractor over seven months. Software engineer Liza Daly was selected to research and build a proof-of-concept for CC Search, a project which she understood to be “a front door to the universe of openly licensed content.”
“CC Search is meant to make material more discoverable regardless of where it is hosted,” Daly said. “For this reason (and for obvious cost-saving objectives), we decided to host only image metadata — title, creator name, any known tags or descriptions — and link directly to the provider for image display and download. A consequence of this is that CC Search only includes images which are currently available on the web; CC is not collecting or archive any images itself.”
Daly built the search feature on AWS cloud infrastructure using Python, Django, Postgres, and Elasticsearch. The beta has estimated hosting costs of $1,400/month. She opted for Python, because she was most familiar with it.
“As the prototype evolved, we decided the opportunity for an engaging front door to the Commons lay in curation and personalization,” Daly said. “Because of its dedicated maintenance team and frequent patch management, I chose Django as the web framework.” She chose Elasticsearch over Solr (and other options) primarily because of the AWS’s Elasticsearch-as-a-service.
“CC Search is not, at this time, a particularly sophisticated search application; image metadata is relatively simple and when dealing with a heterogeneous content set from a diversity of providers, one tends towards a lowest-common-denominator approach — our search can only be as rich as our weakest data source,” Daly said. “There is much to be improved here.”
Daly also described an interesting idea for adding a blockchain-type architecture that would record licensing transactions, sharing, and gratitude in a distributed way. This idea falls outside of the scope of the MVP but may be something the project’s future developers will consider when implementing the final version.
“A long-term goal of this project is to facilitate not only search and discovery, but also reuse and ‘gratitude,’” Daly said. “A frequent complaint about open licenses in general — both for creative works and software code — is that contributing to the commons can be a thankless task. There are always more consumers than contributors, and there’s no open web equivalent to a Facebook ‘like.’”
Other future improvements that the team will consider based on user feedback include adding more content partners, more tools for customizing lists, allowing users to search from their own curated material, and giving trusted users the ability to push metadata back into the collection. Search filters may also be expanded to allow for searching by color, drilling down into tags, and searching public lists.
Check out the beta for the new CC Search at ccsearch.creativecommons.org.
Where’s the WordPress plugin?!
An opt-in would be nice, with access to users’ images. For example, if I add the search to my site (as a WordPress plugin), I would like to have a checkbox saying something along the lines of:
“I would like to include my images in the CCSearch repository. I agree with the legal terms, this and that.”
Just an idea.